Overview
About the data
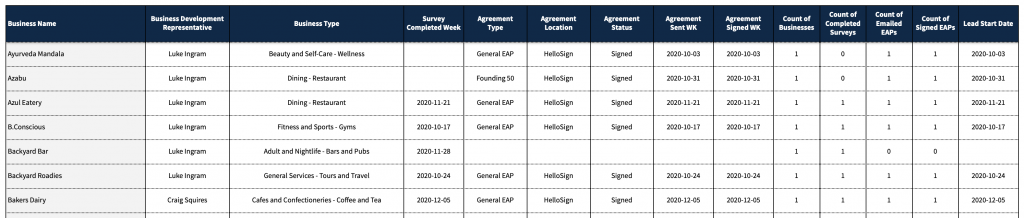
- Provided is dummy dataset for the SP data from the first three (3) months of 2021. Basic measures are included to get to high level summary insights.
- As a dummy dataset, intuitions around which categories and states have activities may not align. Ex: Snow Removal services in Florida may be included in the dataset even though snow is rare in Florida.
- Spend is the amount SPs budget for a given period. This amount typically stays the same across months, though it can increase and/or decrease. If spend decreases this represents churn. Note that spend can be used to get Revenue Run Rate.
- Churn % is a key metric when evaluating SPs and is calculated: Churn / Spend.
- Please note that this is a dummy dataset and
Goals
- Evaluate the dataset using Google Data Studio to identify trends and gain insights to help inform changes to strategic initiatives
- Create a presentation of your findings and answer the following questions:
- Explain the trends for Spend and Churn. Which areas were hit hardest by Churn %?
- Where would you focus to improve Spend?
- A recent strategic initiative was to cease offering ads in low Spend categories. Where do you see evidence of this initiative? How is it currently performing? What additional categories would you recommend eliminating and why?
- What additional dimensions, measures, and/or datasets would you like to have to further expand this analysis?
- Which categories, if any, are impacted by seasonality?
Presentation
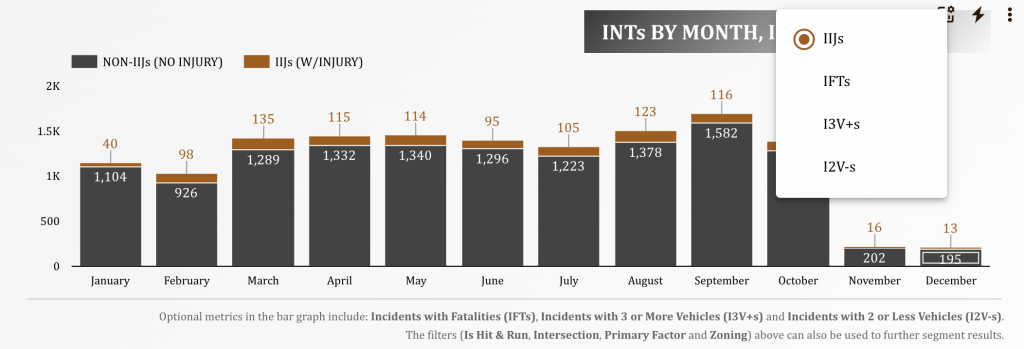
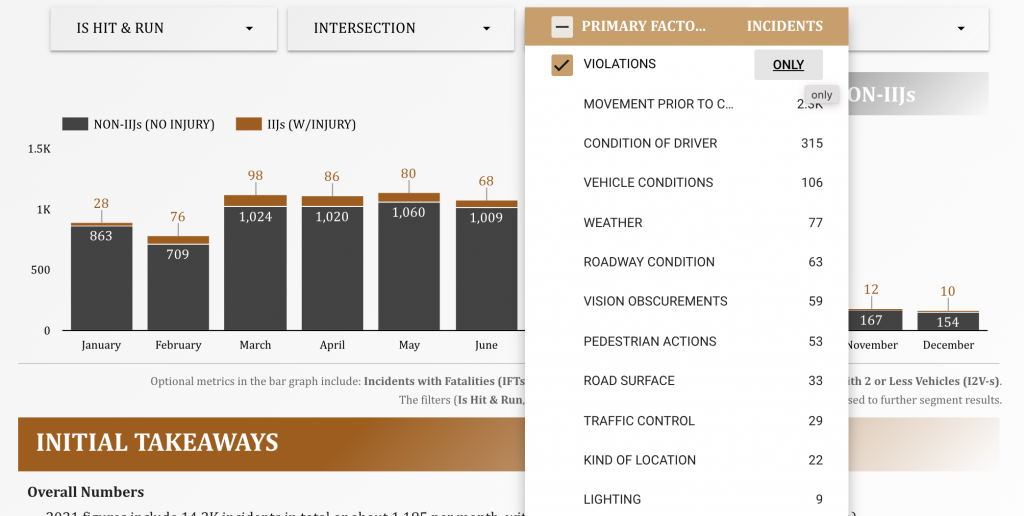
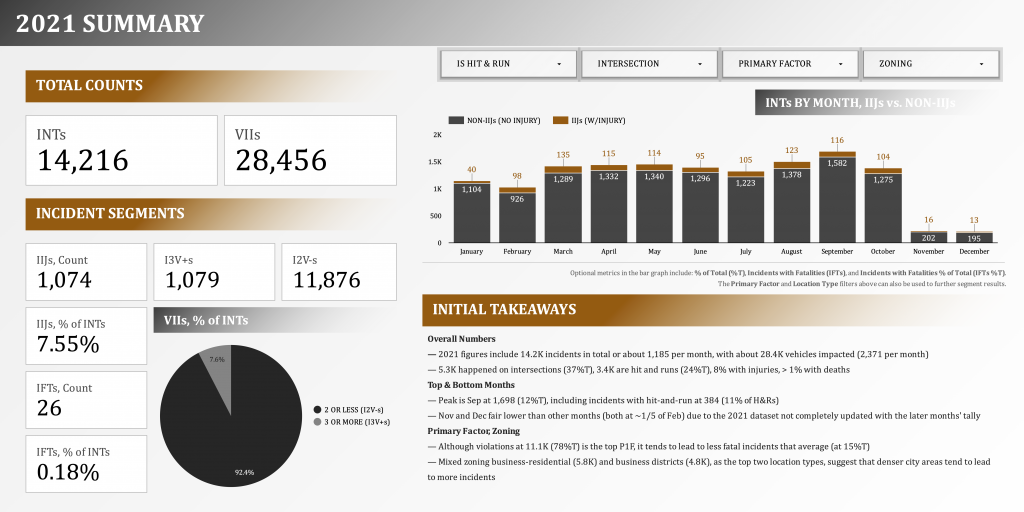
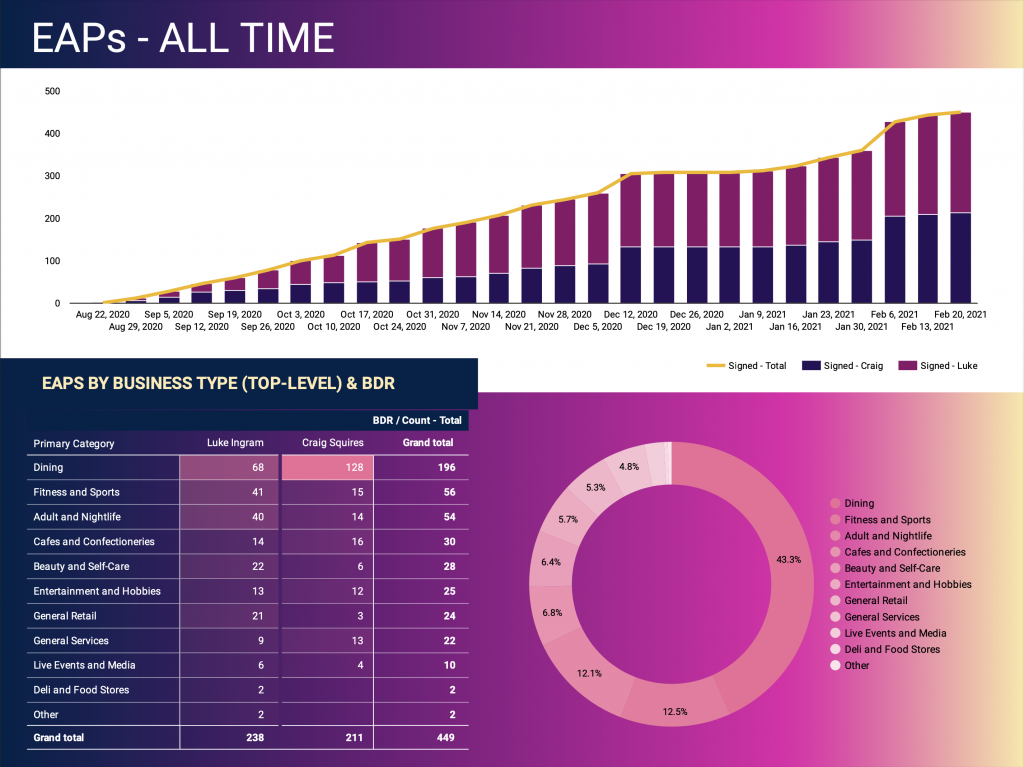
Below is a snapshot of the second page of the presentation (after the presentation overview page). Please click the image to go to the dynamic dashboard.